Multimodal Disambiguation
Improved task completion by 4% by optimizing contact and device name disambiguation/clarification on devices with screens
Background:
Alexa Communications is one of the most complex domains, requiring the highest number of multiturn dialogs as compared to others like Alexa Music, or Home Productivity (Timers and Alarms, Reminders). In particular, Calling relies on complex Connection Resolution logic for contact/device name disambiguation.
Customer Problem:
With speech/NLU based systems, disambiguation is one of the most challenging problems, particularly when names (of people or devices) are involved. When customers had a large contact list, for example, with 7 contacts named "Chris" and then simply asked to "call Chris" there would be a need to determine which one. But with such a large number of matches, the TTS would be too long if every option was read out loud. Generally, the "rule of threes" dictates that only 3 choices can be held in working memory at a time. There were many disambiguation challenges in the Alexa Communications domain like this, such as:
-
Similar device names: Echo Show 1 vs Echo Show 2
-
First name spoken, many contacts with the same first name and different last names
-
Same name with different spellings (Amy vs. Aimee)
-
Similar sounding names, Lisa vs. Liza

Process & Solution(s):
Looking at the disambiguation across devices, I determined how the TTS for screened vs. audio-only devices could be optimized. First, this involved making the TTS as specific as possible without being verbose, i.e. "Which contact: A or B?" is actually more effective than simply "A or B?" even though it is slightly longer. This proved out in usability testing, particularly when the names were poorly pronounced by TTS.
For devices with screens, I worked closely with my UX design partner and our researchers to A/B test different versions of the disambiguation screen that allowed the customer to view their choices and tap them as well as speak their responses. To design the screens for testing, we dove deep our internal team's research about the "redundancy effect" in education, which found that students learn better from multimedia lessons containing graphics and narration than from graphics, narration, and redundant on-screen text. Following this guidance, we minimized clutter and designed the screens to support but not exactly duplicate the spoken TTS.
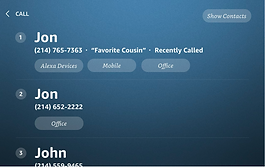
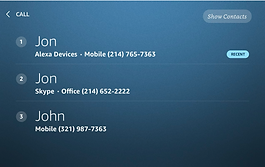





Results:
After A/B testing and customer beta the optimal screen design, production data showed a 4% increase in successful task completion, i.e. placing a call to the correct contact. Results showed that customers rarely transitioned from voice to touch; however they used the screen as a resource to understand how to more clearly indicate via voice which contact/device they wanted.
This work let to multiple multimodal patterns for disambiguation, and later confirmation as well. The results are consistently referenced as best practices in voice and screen multimodal design both at Amazon and in industry, and were presented at conferences Unparsed London and Voice & AI in 2023.

